
Literate Programming, Reproducible Research, and "Clean Code" + Docstrings
What is “Literate Programming”?
Donald Knuth formally introduced the idea of “Literate Programming” in 1984 (Knuth, 1992). In his book he suggested the following change in attitude within the construction of programs:
Instead of imagining that our main task is to instruct a computer what to do, let us concentrate rather on explaining to human beings what we want the computer to do.
At Stanford University the idea of literate programming was realized through
the WEB system. It involves combining a document formatting
language with a programming language (Knuth, 1992). In the original report
submitted to The Computer Journal in 1983, the example presented of the
WEB system consisted of the combination of TeX, and PASCAL. This
choice is not surprising, as Donald Knuth created TeX. The code was written
in a single .WEB file. A reason Knuth was happy with the term WEB is
because he considered a complex piece of code as a web simple
materials delicately placed together (Knuth, 1992). The ‘weaving’ process
involves separating out the document formatting language into a separate
file. While the ‘tangling’ entails extracting the programming language to
produce a machine-executable code (Knuth, 1992). This process was depicted
as figure 1 (Knuth, 1992).
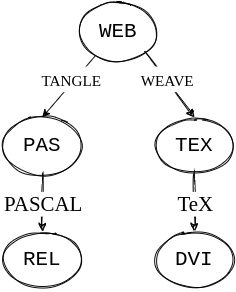
Figure 1: Adopted image from the original paper showing dual usage of a .WEB file. The ‘weaving’ separates out the TeX from the .WEB file compiles it to an output document, while the ‘tangling’ extracts the PASCAL code to produce a machine-executable program.
If you consider using a tool for literate programming their website has a long list of tools which can be used for writing code with literate programming (“More Tools”). While it is comprehensive, it does not list a fantastic tools which will be mentioned later. There are also several other projects online which seem to be popular, such as Zachary Yedidia’s Literate project.
Data Science and Reproducible Research
The term “data science” likely first appeared in 1974 and initially defined by the following quote (Cao, 2017).
The science of dealing with data, once they have been established, while the relation of the data to what they represent is delegated to other fields of data.
The term has increased in popularity since 2012 (Cao, 2017). This increase in interest is likely due to the emergence of data mining, big data and the advances in Artificial Intelligence (AI) and Machine Learning (ML). Due to the accumulation of large amounts of data, interdisciplinary tools are being combined with to form a “new” field. A more modern and comprehensive definition of data science is as follows (Cao, 2017).
From the disciplinary perspective, data science is a new interdisciplinary field that synthesizes and builds on statistics, informatics, computing, communication, management, and sociology to study data and its environments (including domains and other contextual aspects, such as organizational and social aspects) in order to transform data to insights and decisions by following a data-to-knowledge-to-wisdom thinking and methodology.
A central point in literate programming is the intent of ‘weaving’ and ‘tangling’ the original document into two separate files. The original web document was not necessarily intended to be used as the final result. However, the modern use of “reproducible research” implies using a similar literate programming web document as the final result (Goodman, Fanelli, & Ioannidis, 2018).
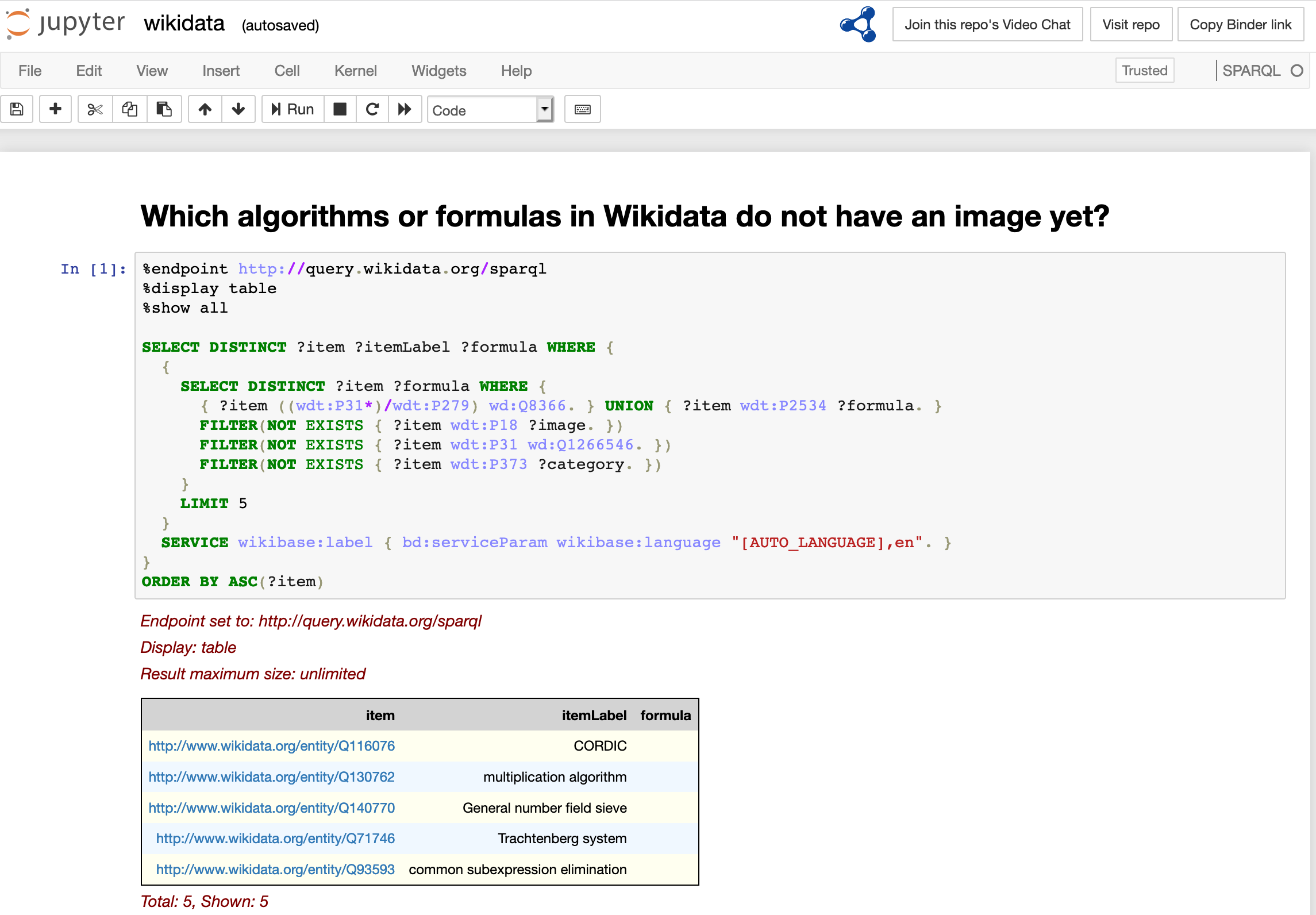
Figure 2: Example of a Jupyter Notebook showing the mix of rich text, code block, along with output.
The computer scientist Jon Claerbout coined the term “reproducible research” and described it with a reader of a document being able to see the entire process from the raw data to the code producing tables and figures (Goodman et al., 2018). The term can be slightly confusing, as reproducibility has long been an important part of the research and the scientific method.
One of the issues in with the use of software in scientific field generally, is the reproducibility of the research being conducted (Hinsen, 2013). Therefore, the greater context surrounding the code is more important and possibly not self explanatory through the code alone. Experts within the field of exploratory data science even struggle keeping track of the experiments they conduct. It can lead to confusion of what experiments have been performed and how they came by the results (Hinsen, 2013). Since digitalization and digital tools have become a more important part of many fields, reproducible research has become popular in such fields such as epidemiology, computational biology, economics, and clinical trials (Goodman et al., 2018).
While literate programming and reproducible research are closely related in form, they were intended for slightly different use-cases. Literate programming is not specifically for research, but is a more broad approach to programming. While reproducible research focuses on providing the full context of an experiment or study and not making the code itself more legible.
Some of the more popular tools for reproducible research are
Jupyter Notebooks for programming in python (example in figure
2), and the integration of SWeave and knitr into R
Markdown for programming in the statistical language R (Kery, Radensky, Arya, John, & Myers, 2018).
Jupyter Notebooks is an open source spin-off project from the IPython
(Interactive Python) project. Python is considered a fairly easy language to
learn, there are several python projects for both data manipulation, and
support for different machine learning frameworks such as Tensorflow and
PyTorch. This makes Jupyter Notebooks particularly well suited for data
science.
Readable and Clean Code
Knuth’s attitude change mentioned above was primarily about making code more readable for humans. Literate programming is a method of accomplishing this goal, but it is not the only avenue to take. What if the code was written so well, it was completely self-explanatory.
Robert C. Martin, affectionately called “Uncle Bob”, is a software engineer and the author of the bestselling book Clean Code: A Handbook of Agile Software Craftsmanship (Martin & Coplien, 2009). He has an interesting talk on clean code where he explains that code should read like “well written prose”. In his book he writes (Martin & Coplien, 2009):
Indeed, the ratio of time spent reading versus writing is well over 10 to 1. We are constantly reading old code as part of the effort to write new code. …[Therefore,] making it easy to read makes it easier to write.
While writing readable code is something to always strive towards, it will likely never be completely self-explanatory. Therefore, it would likely be beneficial to write good documentation to complement the code.
Self-Documentation with Docstrings
Emacs has a nice method of self-documentation which is very helpful
to understanding the editors source code written in elisp. It
uses documentation strings (or docstrings), which are comments directly
written into the code. Writing comments in code to describe functions is not
at all uncommon. However, traditional in-file documentation is stripped
from the source during runtime, such as Javadocs. Docstrings are maintained
throughout the runtime of the code in which it is written. The programmer
can then interactively inspect this throughout the runtime of the program.
Some notable languages which support Docstrings include:
- Lisp/Elisp
- Python
- Elixir
- Clojure
- Haskell
- Gherkin
- Julia
Emacs is almost like working in an lisp terminal. The editor is written
entirely in a variant of lisp, called elisp. For example, in order to
split a window vertically, the function split-window-below is called. The
code snippet below is the start of the source code for this function.
(defun split-window-below (&optional size)
"Split the selected window into two windows, one above the other.
The selected window is above. The newly split-off window is
below and displays the same buffer. Return the new window.
If optional argument SIZE is omitted or nil, both windows get the
same height, or close to it. If SIZE is positive, the upper
\(selected) window gets SIZE lines. If SIZE is negative, the
lower (new) window gets -SIZE lines.
If the variable `split-window-keep-point' is non-nil, both
windows get the same value of point as the selected window.
Otherwise, the window starts are chosen so as to minimize the
amount of redisplay; this is convenient on slow terminals."
(interactive "P")
(let ((old-window (selected-window))
(old-point (window-point))
(size (and size (prefix-numeric-value size)))
moved-by-window-height moved new-window bottom)
(when (and size (< size 0) (< (- size) window-min-height))
;; `split-window' would not signal an error here.
(error "Size of new window too small"))
;; ...
;; ...
;; ...
When calling the function describe-function and inputting the function
name, “split-window-below”, it will generate the following output in a
mini-buffer (a kind of little buffer). This documentation is created
dynamically during runtime.
split-window-below is an interactive compiled Lisp function in ‘window.el’.
It is bound to SPC w -, SPC w s, M-m w -, M-m w s, C-x 2,
. (split-window-below &optional SIZE)
Probably introduced at or before Emacs version 24.1.
Split the selected window into two windows, one above the other. The selected window is above. The newly split-off window is below and displays the same buffer. Return the new window.
If optional argument SIZE is omitted or nil, both windows get the same height, or close to it. If SIZE is positive, the upper (selected) window gets SIZE lines. If SIZE is negative, the lower (new) window gets -SIZE lines.
If the variable ‘split-window-keep-point’ is non-nil, both windows get the same value of point as the selected window. Otherwise, the window starts are chosen so as to minimize the amount of redisplay; this is convenient on slow terminals.
[back]
Comparing the docstring in the source code and the output of
describe-function, there is more information added to the output
documentation. This was a slight aside, but using describe-* functions in
Emacs is probably of the most useful and helpful ways to learn emacs.
However, this does show a benefit of how docstrings are used in emacs.
Org-Mode for Literate Programming and Reproducible Research
While Jupyter Notebooks are a fantastic way of writing reproducible
research, they are not a method of literate programming as they are not
intended to be ‘weaved’ and ‘tangled’. The original tool such as WEB
system for literate programming, does not allow for compiling embedded code
interactively. However, Org-mode was the first to provide full support for
reproducible research and literate programming (Schulte, Davison, Dye, & Dominik, 2012).
Org-mode is something called a major mode in emacs. An .org file is essentially
a plain text markup language, but there are so many things that can be done
in org-mode it is mind-boggling. With some configuration it can be used as
almost anything including an advanced agenda system, calendar, financial
ledger, zettlekasten note taking system (org-roam), and an exporter into
almost any text formatting. Even that was an inadequate list, but for those
interested this is a more complete list.
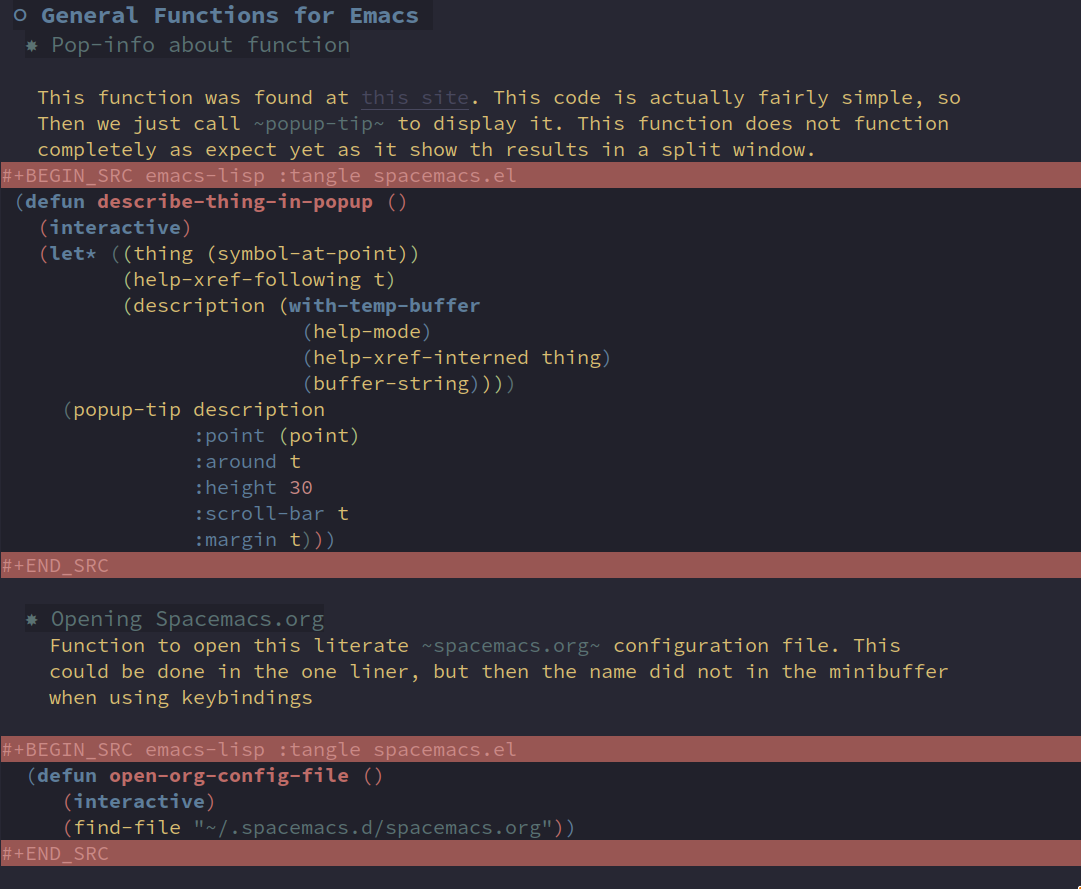
Figure 3: An example of a .org file with code blocks in emacs-lisp which will be tangled to a file called spacemacs.el.
Using a package called org-babel it can allow for both ‘weaving’ using
org-mode’s built in export functionality, and ‘tangling’ using
org-babel-tangle of the entire file (see figure 3). As with other markup languages,
.org files already support rich text formatting of code blocks. With
simple tags and commands the code can run code blocks can be run dynamically
by using certain session tags. Running embedded code blocks in this manner
through the same, or multiple, sessions in the same file is important for
reproducible research. More details on using org-mode for both literate
programming and reproducible research is the paper by (Schulte et al., 2012).
A blog post which explains and demonstrates how to use org-babel can be
found here.
Closing thoughts
While literate programming is the a useful tool for providing more context to programming projects, in many cases writing self-explanatory code might be the best avenue for pure software engineering. Reproducible research is more suited for explaining a study or an experiment which is particularly useful in the scientific practice today as the use of digital tools continues to grow. Contrary to software engineering, these use-cases aren’t well suited for simply writing self-explanatory code. Literate programming and reproducible research attack mixed natural language and computational language documents for different ends (Schulte et al., 2012). While literate programming introduces natural language to programming files, reproducible research adds embedded executable code into natural language documents (Schulte et al., 2012).
If humans were capable of easily writing in machine code, there would be no need for all the different types of programming languages. The reason we use programming languages is to be able to interpret and understand what we are instructing the computer to do. Therefore, making the code understandable should be a top priority. Even though Knuth’s literate programming might not be suitable in all settings, I think his attitude about telling the reader what we are instructing the machine to perform is valuable in any programming situation. This is especially true for collaboration and long term complexity of coding projects.
While some of the differences between literate programming and reproducible research have been mentioned, particular examples of literate programming were not discussed. Configuration files are ideal for literate programming. They typically require explanations of the context of the settings or an explanation of the setting itself. After writing the literate configuration, they can be tangled to generate the actual configuration. I hope to write a post soon about showing how I created a literate configuration for spacemacs.
Bibliography
Cao, L. (2017, June). Data science: A comprehensive overview. ACM Comput. Surv., Vol. 50, pp. 1–42. Association for Computing Machinery. Retrieved from https://dl.acm.org/doi/10.1145/3076253
Goodman, S. N., Fanelli, D., & Ioannidis, J. P. (2018). What does research reproducibility mean? In Get. to Good Res. Integr. Biomed. Sci. (Vol. 8, pp. 96–102). Springer International Publishing. Retrieved from www.ScienceTranslationalMedicine.org
Hinsen, K. (2013). Software development for reproducible research. Comput. Sci. Eng., /15/(4), 60–63.
Kery, M. B., Radensky, M., Arya, M., John, B. E., & Myers, B. A. (2018). The Story in the Notebook: Exploratory Data Science using a Literate Programming Tool. Retrieved from https://doi.org/10.1145/3173574.3173748
Knuth, D. E. (1992). Literate programming. In Cent. Study Lang. Inf.
Martin, R. C., & Coplien, J. O. (2009). Clean code: a handbook of agile software craftsmanship. Upper Saddle River, NJ [etc.]: Prentice Hall. Retrieved from https://www.amazon.de/gp/product/0132350882/ref=oh%5Fdetails%5Fo00%5Fs00%5Fi00
Schulte, E., Davison, D., Dye, T., & Dominik, C. (2012). A multi-language computing environment for literate programming and reproducible research. J. Stat. Softw., /46/(3), 1–24. Retrieved from https://www.jstatsoft.org/index.php/jss/article/view/v046i03/v46i03.pdf https://www.jstatsoft.org/index.php/jss/article/view/v046i03
More Tools. Lit. Program. Retrieved from http://www.literateprogramming.com/tools.html